秋招结束了,博主在字节 ssp,拼多多 ssp 和 阿里 A sp 中选择了阿里,虽然字节和拼多多的薪资高出不少,但是阿里是楼主一直想去的公司,然后觉得应届生应该以之后的发展为主,所以选择了阿里~
👇是秋招的面试总结,有缘人可以参考一下
-
快手 —— abtest 部门 —— 数据研发工程师(offer)
7.29 直通终面 + hr面,8.9 意向书,10.17 offer
因为之前暑期三面全过,因此这次提前批,算是直通终面吧,一轮长达一个半小时的技术面之后,进行了 hr 面试
-
一个 uid,p_date 的 hive 表,计算 7 留
select t1.p_date as p_date, count(distinct t2.uid) / count(distinct t1.uid) as 7_retain from t t1 left join t t2 on t1.uid = t2.uid and datediff(t2.p_date, t1.p_date) >= 1 and datediff(t2.p_date, t1.p_date) <= 7 group by t1.p_date; -
一个 referer 的 hive 表,计算 top 10 的 referer
select referer, count(*) as num from t group by referer order by num desc limit 10; -
一个 referer,url 的 hive 表,计算 top 10 的跳出 url(需要用 url join referer)
select t1.url, count(*) as num from t t1 join t t2 on t1.url = t2.referer group by t1.url order by num desc limit 10; -
flink 源码相关
感兴趣的同学可以参考 flink 流式处理源码
-
redis 如何持久化
AOF + RDB
-
-
阿里 —— 淘系技术部 —— Java 研发工程师(offer)
8.6 一面,8.7 二面,8.12 三面,8.14 四面,8.15 HR面,9.12 意向书,10.31 offer
-
一面
-
深入理解 JVM,从头开始背完事了
-
双线程交替打印字符串
class Thread1 implements Runnable { private static final String s = "This is a coding test"; private Semaphore self; private boolean first; public Thread1(Seamphore self, Seamphore next, boolean first) { this.self = self; this.first = first; } public void run() { int length = s.length(); int idx = first ? 0 : 1; while (idx < length) { semaphore.acquire(); System.out.print(s.charAt(idx)); idx += 2; next.release(); } } } -
n 线程交替打印字符串
class Thread2 implements Runnable { private static final String s = "This is a coding test"; private Semaphore self; private Semaphore next; private int index; private int threadNum; public Thread2(Semaphore self, Semaphore next, int index, int threadNum) { this.self = self; this.next = next; this.index = index; this.threadNum = threadNum; } public void run() { int length = s.length(); while (index < length) { self.acquire(); System.out.print(s.charAt(index)); this.index = index + this.threadNum; next.release(); } } }
-
-
二面
-
常见的排序算法,讲出算法复杂度和稳定性
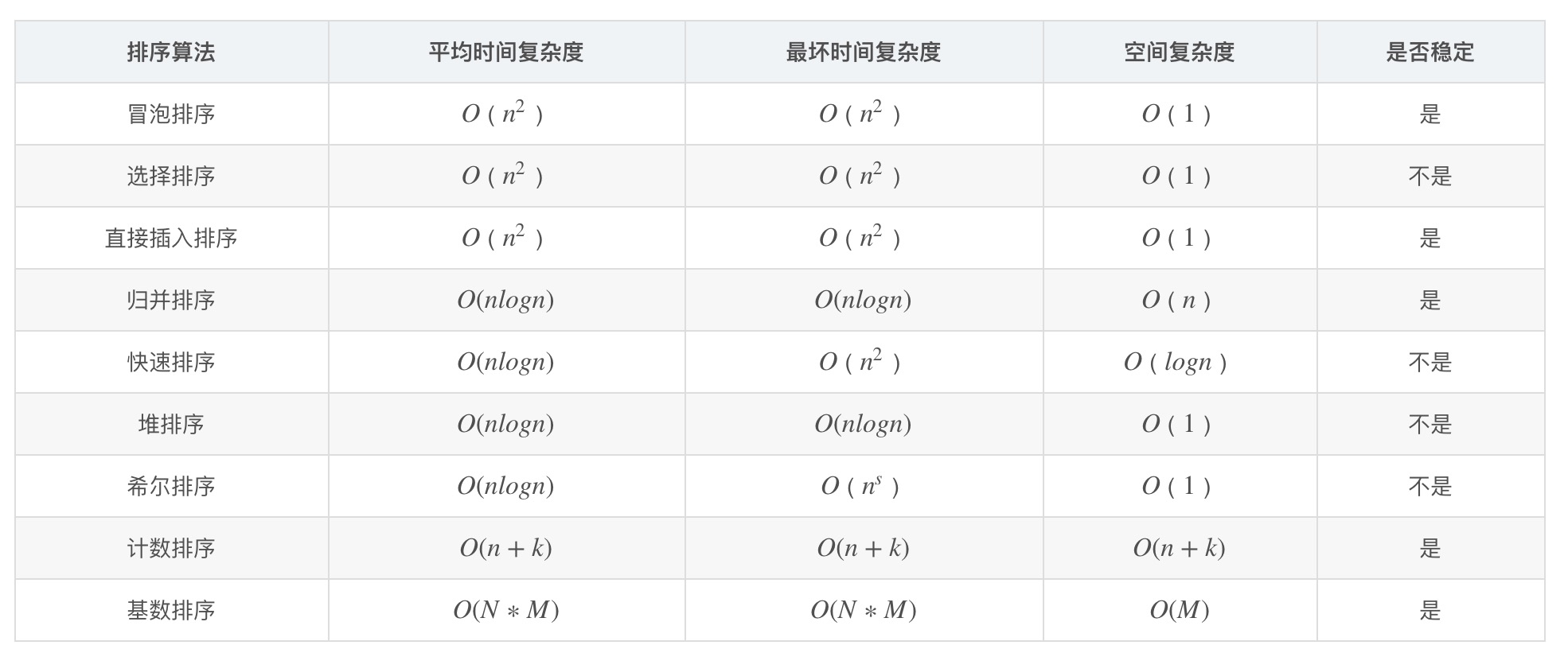
-
讲一下快速排序的实现
def quick_sort(self, arr, head, tail): """ 快排 type arr: list 待排序的数组 type head: int 起始索引 type tail: int 终止索引 rtype: list """ def partition(arr, head, tail): """ 获取快排中用于分割数组的元素的索引 type arr: list 待排序的数组 type head: int 起始索引 type tail: int 终止索引 rtype: int """ base_num = arr[tail] i = head for j in xrange(head, tail): if arr[j] < base_num: arr[i], arr[j] = arr[j], arr[i] i += 1 arr[tail], arr[i] = arr[i], arr[tail] return i if head < tail: middle = partition(arr, head, tail) self.quick_sort(arr, head, middle - 1) self.quick_sort(arr, middle + 1, tail) -
hash 表解决 hash 冲突的方法
- 开放地址法
- 再哈希法
- 拉链法
- 公共缓存区
-
HashMap 的实现方式
-
平衡树
平衡树是的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树
常见的平衡树:2 - 3 搜索树,AVL,红黑树
-
操作系统进程和线程
-
JVM 的内存模型
程序计数器,java 虚拟机栈,本地方法栈,堆,方法区按个解释
-
进程间通信的方式
-
常用的 Linux 命令
ls,cd,top,lsof,netstat,grep,awk,sed
-
讲一下实习经历
自行发挥
-
为什么要从 Web 开发转岗大数据
自行发挥
-
讲一下 NSQ 的实现
-
JVM GC 算法
-
接口延迟太高,如何排查
- 多尝试,是不是稳定复现
- 查看是否限流
- 查看是不是 Redis key 失效了
- 数据库是不是在刷新 insert buffer
- SQL 是否没有建索引
- Java 频繁触发 full gc,查看是否存在内存泄漏/内存溢出
-
如何搭建一个数据仓库
分层搭建
- dim 层 - 维度层
- dwd 层 - 事实层
- dwa 层 - 聚合层
- app 层 - 应用层
-
Java String 类拼接的时候编译器优化
-
-
三面
-
介绍一下实习
自行发挥
-
介绍一下自己如何学习的
自行发挥
-
Nsq 源码介绍一下
-
Flink 源码介绍一下
-
Vue 源码介绍一下
-
之后的打算,计划
自行发挥
-
-
四面
-
介绍一下实习
自行发挥
-
HBase 架构
-
Flink 介绍一下
-
进程间通信的方式
-
TCP 11 种状态
-
ArrayBlockingQueue 源码
-
1000 个苹果,放到 10 个篮子,如何分配,能够得到 1 - 1000 中任意的苹果数目
二进制分法,1,2,4…
-
为什么要出来面试
自行发挥
-
-
hr 面
-
大学如何学习的
自行发挥
-
保研还是考验
保研
-
比较一下头条和阿里两个公司
自行发挥
-
未来什么规划
自行发挥
-
有没有女朋友
自行发挥
-
-
-
百度 —— 智能云 —— 大数据开发工程师(offer)
8.10 一面 - 三面,9.23 OC,10.8 offer
-
一面
-
HDFS 原理
-
YARN 原理
-
MR 原理
-
Spark 原理
-
线程、进程
线程是 CPU 调度的最小单位,进程是内存分配的最小单位
-
CPU 如何进行时间片轮转
硬件层面,通过时间中断实现的
-
红黑树
-
Java 反射,动态代理
-
快速排序
def quick_sort(self, arr, head, tail): """ 快排 type arr: list 待排序的数组 type head: int 起始索引 type tail: int 终止索引 rtype: list """ def partition(arr, head, tail): """ 获取快排中用于分割数组的元素的索引 type arr: list 待排序的数组 type head: int 起始索引 type tail: int 终止索引 rtype: int """ base_num = arr[tail] i = head for j in xrange(head, tail): if arr[j] < base_num: arr[i], arr[j] = arr[j], arr[i] i += 1 arr[tail], arr[i] = arr[i], arr[tail] return i if head < tail: middle = partition(arr, head, tail) self.quick_sort(arr, head, middle - 1) self.quick_sort(arr, middle + 1, tail) -
二分查找
def binary_search(arr, target): l, r, m = 0, len(arr) - 1, -1 while l <= r: m = l + (r - l) / 2 if target == arr[m]: return True elif target > arr[m]: l = m + 1 else: r = m - 1 return False -
设备连接路由表,路由表对外的 IP 是相同的,如何区分是哪个设备
路由表中存在映射,端口号 -> 真实 ip
-
Hive 中的元数据存储
首先需要搞清楚,Hive 中数据存储的位置,元数据(对数据的描述,包括表,表的列及其它各种属性)是存储在 MySQL 等数据库中的,因为这些数据要不断的更新、修改,不适合存储在 HDFS 中
-
判断链表有环的快慢指针的证明
-
-
二面
-
HBase 架构
-
MySQL B+ 树,MySQL 四种隔离级别,MVCC
-
MySQL 查询计划生成以及优化
-
Redis 数据淘汰策略
-
Redis 持久化
RDB + AOF
-
Nsq 介绍一下
-
Flink 介绍一下
-
-
三面
三面聊人生,理想,以及面试官对百度云未来的展望,面试官介绍了国内的云市场,以及其他厂商的不足,学习了很多
-
-
头条 —— 广告系统 —— 大数据工程师,转正加面(offer)
8.11 转正加面,8.15 意向书,10.31 offer
-
介绍自己做的事情
自行发挥
-
介绍为什么要从 Web 转岗大数据
自行发挥
-
Flink 原理,越详细越好
-
算法题
Leetcode 第四题,自行 google
-
-
猿辅导 —— 数据中台 —— 数据研发工程师(offer)
8.12 一面 - 三面,8.29 意向书,10.23 offer
-
一面
-
两个 字符串,str1 和 str2,计算 str1 - str2 的值,不能转为整型进行计算
def solution(str1, str2): if str1 == str2: return '0' len1, len2 = len(str1), len(str2) symbol = 1 if len1 == len2: for i in xrange(len1): if str1[i] < str2[i]: symbol = -1 str1, str2 = str2, str1 break elif len1 < len2: symbol = -1 len1, len2, str1, str2 = len2, len1, str2, str1 carry = False res = [] for i in xrange(max(len1, len2)): ch1 = int(str1[len1 - 1 - i]) if carry: ch1 -= 1 if i < len2: ch2 = int(str2[len2 - 1 - i]) ch1 -= ch2 if ch1 < 0: ch1 += 10 carry = True else: carry = False res += str(ch1), ans = res[::-1] while ans and ans[0] == '0': ans.pop(0) return ''.join(ans) if symbol == 1 else '-' + ''.join(ans) -
最长摆动序列,Leetcode 376
def wiggleMaxLength(self, nums): """ :type nums: List[int] :rtype: int """ length = len(nums) if length < 2: return length dp = [[0] * 2 for _ in xrange(length)] dp[0] = [1, 1] for i in xrange(1, length): if nums[i] > nums[i - 1]: dp[i][0] += dp[i - 1][1] + 1 dp[i][1] = dp[i - 1][1] elif nums[i] < nums[i - 1]: dp[i][1] += dp[i - 1][0] + 1 dp[i][0] = dp[i - 1][0] else: dp[i] = dp[i - 1] return max(dp[-1])
-
-
二面
-
实习和项目经历
自行发挥
-
-
三面
-
零钱问题,Leetcode 518
def solution(coins, target): dp = [0] * (target + 1) dp[0] = 1 for c in coins: for i in xrange(c, target + 1): dp[i] += dp[i - c] return dp[target] -
Flink 原理
-
对大数据的理解
大数据类的工作可以分为三种,inf 方向,数据平台方向,以及数据研发方向
-
如何实时同步 MySQL -> HDFS
MySQL binlog -> Kafka -> 服务消费 Kafka,将更新写到 HDFS 上,然后根据 timestamp 来区分新数据
-
-
-
网易 —— 网易云音乐 —— 大数据开发工程师(二面挂)
8.16 一面,8.21 二面,每面 20 分钟,然后就被挂了。。。
-
一面
-
项目经历
自行发挥
-
Flink 原理
-
Spark 数据倾斜如何解决
-
Kafka 原理
-
-
二面
-
项目经历
自行发挥
-
Flink 的状态后端如何存储
-
MR 的过程
-
数仓如何分层
dim,ods,dwa
-
有没有阅读过数仓相关的书籍
没有
-
-
-
第四范式 —— 数据中台 —— 大数据开发工程师(offer)
8.17 一面,8.20 二面,9.1 三面,9.14 意向书,11.1 offer
-
一面
-
Flink 原理
-
Kafka offset 存放位置
老版本存放在 ZK 上,新版本存放在全局 topic 上
-
Spark Stage 如何划分
-
Java 双亲委派模型
-
算法题 - 链表反转
class ListNode(object): def __init__(self, v): self.v = v self.next = None def solution(head): res = ListNode() tmp = res while head: next_node = head.next head.next = tmp.next tmp.next = head head = next_node return res.next -
算法题 - 两个链表是否相交,问思路
两个链表长度为 len1,len2,较长的链表先走 len1 - len2 步,然后两个链表再一个走一步,如果节点相交,则两个链表相交
-
-
二面
-
项目经历
自行发挥
-
Hive,Spark 如何解决数据倾斜
-
Flink 如何实现 exactly once
-
介绍第四范式的大数据平台
-
-
三面
-
项目经历
自行发挥
-
介绍第四范式的大数据平台
-
讲讲 Flink 源码
-
大数据批流处理架构
-
-
-
腾讯 —— 腾讯音乐 —— 大数据研发工程师(offer)
8.18 一面,8.28 二面,9.9 三面,9.12 HR面,9.17 意向书,9.27 offer
-
一面
一面的面试官十分奇葩,因为我语速快觉得我人毛躁,一直问我会不会和同事吵架,也不想听我的实习,体验十分不好。。。
-
算法题 - 非递归二叉树前序遍历
class TreeNode(object): def __init__(self, v): self.v = v self.left = None self.right = None from collections import deque def solution(root): if not root: return q = deque([root]) while q: cur_node = q.pop() print cur_node.v if cur_node.right: q.append(cur_node.right) if cur_node.left: q.append(cur_node.left) return -
算法题
最小非零元素
牛牛给了小Q一个长度为n正整数序列ai
牛牛要求小Q重复以下操作步骤k轮
1、发现最小的非零元素x
2、打印x
3、将序列中所有非零元素减x
def solution(nums, k): length = len(nums) nums.sort() n_idx, k_idx = 0, 0 res, delta = [], 0 while n_idx < length and k_idx < k: if nums[n_idx] > delta: res.append(nums[n_idx] - delta) delta = nums[n_idx] k_idx += 1 n_idx += 1 if k_idx < k: res += [0] * (k - k_idx) return res -
Flink 原理
-
Java GC,包括 GC 算法,GC 垃圾收集器,GC 发送在什么时候,做了什么事情,以及可达性分析 gg 的是否会被马上清除
-
Spark 数据倾斜如何做
-
大数据中 Lambda 架构和 Kappa 架构
-
-
二面
二面面试官人贼贼好,面试很舒服
-
自我介绍
自行发挥
-
项目经历
自行发挥
-
Java 泛型在编译的时候和运行的时候都做了什么
泛型值存在于 Java 的编译期,编译成字节码文件后,泛型是要被擦除的,例如一个 Integer 类型的 ArrayList,add 一个 “hello” 会报错,但是反射调用就没问题
-
Java 反射实现的原理
Java 类加载的时候,会编译生成 .class 字节码文件,会将类的字段、方法的限定符、描述符加载到方法区,同时 Java 对象的对象头中有对 Java 类的引用
-
操作系统如何执行一个可执行文件
操作系统分配 CPU,然后父 SHELL 进程去内核态启动子进程,然后会给子进程分配虚拟内存页(涉及到页面置换算法),子进程执行可执行文件
-
进程、线程和协程之间的区别
-
TCP 的 11 种状态
-
从浏览器输入一个 URL 之后发生了什么
-
HTTP V1、V1.1 和 V2.0 之间有什么变化
-
-
三面
感觉像 hr 面的技术面
-
项目经历
自行发挥
-
你有什么技术特长
自行发挥
-
讲讲工作中遇到的最大的困难
自行发挥
-
讲讲 Flink
-
为什么要投他们
自行发挥
-
-
-
美团 —— 到店事业部 —— 数据研发工程师(offer)
8.20 一面,8.22 二面,8.27 三面 - 五面,8.27 hr 面,9.10 意向书,10.22 offer
-
一面
一面面试官是个小姐姐,面试的时候给我讲了很多数仓方法论的东西,体验非常好
-
项目经历
自行发挥
-
讲讲数据仓库是如何分层的
按照数据的作用
-
讲数仓的模型
雪花 + 星型
-
数仓方法论
不会,小姐姐很耐心的给我讲
-
-
二面
-
项目经历
自行发挥
-
数仓方法论
网易和美团都问了这个,我决定要看一本书了
-
大数据组件的理解
-
-
三面
-
介绍业务
自行发挥
-
Spark 数据倾斜
-
Hive 数据倾斜
-
数仓方法论
- 选择业务过程:我认为这就是理解自己的业务是在做什么
- 声明粒度:精确定义某个事实表的每一行在表示什么
- 确定纬度:确定度量环境中所有可能出现的单值描述符
- 确定事实:确定过程的度量是什么
-
统计抖音城市的日活的事实表
- uid 用户维度
- did 设备维度
- cid 城市维度
- vid 视频 id
- play_num 视频播放次数
- start_time 开始时间
- end_time 结束时间 … 等
-
-
四面
-
介绍业务
自行发挥
-
Flink 原理(exactly once,watermark)
一直在讲 Flink
-
Flink 1.4 之后端到端的一致性如何保证
-
-
五面
-
介绍业务
自行发挥
-
数据倾斜
同三面
-
聊人生,聊理想,给我介绍维度建模
-
-
-
拼多多 —— 数据中台 —— 大数据研发工程师(offer)
8.25 一面,9.5 二面,9.19 HR 面,10.9 意向书
-
一面
吐槽一下微信视频面试。。。
-
Java HashMap
-
Flink 原理
-
MR 的过程
-
项目经历
自行发挥
-
数据仓库分层
维度层,事实层(uuid,维度层外键,度量)
-
Hive 表如下所示,用 SQL 统计每日每个城市新增访问用户数
user_visit( uid bigint, time bigint, city string )SELECT city, dayofyear(FROM_UNIXTIME(time)) as day, COUNT(DISTINCT uid) as new_count FROM ( SELECT uid, city, MIN(time) as time FROM user_visit GROUP BY uid, city ) t group by city, dayofyear(FROM_UNIXTIME(time))
-
-
二面
二面居然还是微信视频面试,不过二面回答我的提问是我面试中体验最好的,很感谢
-
介绍业务
自行发挥
-
数据仓库分层方式
dim 维度,dwd 事实,dwa 聚合层
-
数仓缓慢变化维度解决方法
-
数仓一致性的问题
这个需要区分一致性维度和一致性事实来看
-
一致性维度,构建总线矩阵,跨事实表字段 + 上卷(产品维度和品牌维度对应的字段名和填充值)等保证维度一致性
-
一致性事实,收入、利润等关键指标是必须保持一致的事实,如果事实与不止一个维度模型关联,那么针对这些事实的基本定义和等式,如果针对的是一个事情,是必须相同的,例如两个事实表中的收益单位之类的
-
-
算法题
给出一个数组 [‘a’, ‘b’, ‘c’] 得到所有的排列组成的数组,[‘a’, ‘b’, ‘c’, ‘ab’, ‘ba’…]
def pdd_solution(arr): length = len(arr) if length < 2: return arr res = [] for i in xrange(length): arr[0], arr[i] = arr[i], arr[0] res.append(arr[0]) child_arr = pdd_solution(arr[1:]) for string in child_arr: res.append(arr[0] + string) arr[0], arr[i] = arr[i], arr[0] return res -
如何知道哪个数据指标有用
思考理解业务过程 + ab test + 后验看数
-
Flink 原理
-
-
-
京东 —— 供应链 —— 数据研发工程师(offer)
9.1 一面(面试结束后,面试官还和我握了手,受宠若惊),9.4 二面,9.6 hr 面,9.27 offer
-
一面
-
介绍业务
自行发挥
-
Nsq 源码
-
MR 过程
-
Spark 过程
-
面试官介绍业务
-
-
二面
-
介绍业务
自行发挥
-
Flink 原理
-
Kafka Rebalance
-
Hive 数据倾斜
-
Spark 数据倾斜
-
Spark Driver
-
Nsq 适用场景
因为会丢数据,我觉得 Nsq 仅仅适用于流量侧
-
面试官介绍业务
-
-
-
微软 —— STCA(Bing ads)—— 软件开发工程师(offer)
9.19 一面 - 四面,10.12 意向书,10.16 offer
-
一面
-
介绍业务
自行发挥
-
算法题,有一个数组,取值范围为(0 - 255),给出一个不会出现在数组中的数字 n,进行数组压缩,返回一个 byte 数组(元素范围为 0 - 255)
def solution(arr, n): length = len(arr) if length < 4: return arr res = [] i = 0 while i < length: j = i + 1 while j < length and arr[i] == arr[j]: j += 1 repeat_num = j - i if repeat_num > 3: res.append(arr[i]) while repeat_num > 255: repeat_num -= 255 res.append(n) res.append(repeat_num) else: for idx in xrange(i, j): res.append(arr[idx]) i = j return res -
算法题,给出一个由数字字符串组成的数组,给出拼接这些字符串之后能得到的最大数字
def solution(arr): length = len(arr) if length == 1: return arr[0] def comp(a, b): return a + b <= b + a arr.sort(cmp=comp) return ''.join(arr)
-
-
二面
-
介绍业务
自行发挥
-
蓄水池抽样算法,相同概率找到 target 在 arr 中索引
from random import randint def solution(arr, target): cur_num = -1 res = -1 for idx, n in enumerate(arr): if n == target: cur_num += 1 if randint(0, cur_num) == cur_num: res = idx return res -
并查集算法
class UnionFind(object): def __init__(self, N): """ 初始化参数 type N: int 点的个数 """ self.count = N self.id = [i for i in xrange(N)] self.size = [1] * N def get_count(self): """ 获取并查集中不同种类的点 rtype: int """ return self.count def _find(self, p): """ 查询id指代的节点的根节点 type p: int 节点id rtype: int """ if p != self.id[p]: self.id[p] = self._find(self.id[p]) return self.id[p] def union(self, p, q): """ 在连通图中打通p节点和q节点 type p: int 节点p type q: int 节点q """ p_root, q_root = self._find(p), self._find(q) if p_root == q_root: return False if self.size[p_root] < self.size[q_root]: self.id[p_root] = q_root self.size[q_root] += self.size[p_root] else: self.id[q_root] = p_root self.size[p_root] += self.size[q_root] self.count -= 1 return True -
算法题,查找一个乱序整数数组中,最长连续子序列的长度
def solution(arr): length = len(arr) if length < 2: return length hash_map = {} res = 1 for n in arr: l = hash_map.get(n - 1, 0) r = hash_map.get(n + 1, 0) tmp = l + r + 1 hash_map[n] = tmp if l != 0: hash_map[n - l] = tmp if r != 0: hash_map[n + r] = tmp res = max(res, tmp) return res
-
-
三面
-
介绍业务
自行发挥
-
算法题,判断一个树是否为 BST
class TreeNode(object): def __init__(self, v): self.v = v self.left = None self.right = None def solution(root): if not root: return True res = [True, None] def recursive(node): if not res[0] or not node: return recursive(node.left) if res[1] and res[1] >= node.v: res[0] = False return res[1] = node.v recursive(node.right) recursive(root) return res[0] -
算法题,第 k 个排列,leetcode 第 60 题
def getPermutation(self, n, k): """ :type n: int :type k: int :rtype: str """ tmp = self.helper([i for i in xrange(1, n + 1)], k) return ''.join(map(str, tmp)) def helper(self, arr, k): if k == 1: return arr length = len(arr) tmp = self.get_factorial(length - 1) i = 0 while (i + 1) * tmp < k: i += 1 prefix = [arr[i]] return prefix + self.helper(arr[:i] + arr[i + 1:], k - tmp * i) def get_factorial(self, n): res = 1 for i in xrange(1, n + 1): res *= i return res -
算法题,有一个关注列表 [[‘A’, ‘B’], [‘A’, ‘C’], [‘C’, ‘E’]],如果 ‘A’ 关注了 ‘B’ 那么 A 和 B 是一个组的,求出最后的分组
from collections import defaultdict def solution(arr): cur_idx = 0 ch_2_idx = {} idx_2_ch = {} for a, b in arr: if a not in ch_2_idx: ch_2_idx[a] = cur_idx idx_2_ch[cur_idx] = a cur_idx += 1 if b not in ch_2_idx: ch_2_idx[b] = cur_idx idx_2_ch[cur_idx] = b cur_idx += 1 ud = UnionFind(cur_idx) for a, b in arr: ud.union(ch_2_idx[a], ch_2_idx[b]) res = defaultdict(list) for idx, n in enumerate(ud.id): res[n] += idx_2_ch[idx] return res.values()
-
-
四面
- 算法题,将一个 BST 转变为一个双端链表
我的做法
class TreeNode(object): def __init__(self, v): self.v = v self.left = None self.right = None def solution(root): stack = deque() res = [None, None] def recursive(node): if not node: return recursive(node.left) node.pre = res[1] if not res[0]: res[0] = node else: res[1].right = node res[1] = node recursive(node.right) recursive(root) return res[0]
-
-
FreeWheel —— data inf —— 软件开发工程师(offer)
9.23 一面 - 三面,9.23 HR 面
-
一面
-
介绍业务
自行发挥
-
Hadoop 2.0 HDFS NameNode HA
主备 NameNode + QJM,需要回答出 editlog 和 fsimage
-
Spark 各种问(Driver 运行,数据倾斜,各种 shuffle 等等)
-
算法题,正则匹配,?表示可以匹配任何一个字符,* 表示可以匹配 0 - N 个字符
def solution(s, p): len_s, len_p = len(s), len(p) dp = [[False] * (len_p + 1) for _ in xrange(len_s + 1)] dp[0][0] = True for i in xrange(len_s): for j in xrange(len_p): if s[i] == p[j] or p[j] == '?': dp[i + 1][j + 1] = dp[i][j] elif p[j] == '*': dp[i + 1][j + 1] = dp[i + 1][j] or dp[i][j + 1] or dp[i][j] return dp[len_s][len_p]
-
-
二面
-
介绍业务
自行发挥
-
如何看开源项目的源码
github clone 下来,起 local 环境,打断点,单步调试走通最简单的场景,然后再逐步复杂化
-
有 m 个苹果,一次能够取 1 - n 个,A 和 B 两个人,拿到最后一个苹果的输,A 先开始,请问什么情况下 A 能获胜
只有一个苹果的时候,A 输,2 到 n + 1 个苹果的时候 A 赢,n + 2 输,n + 3 到 2n + 2 赢,2n + 3 输….
-
-
三面
类似 HR 面了,聊人生,聊过去的学习,manager 表示主要想聊聊,看看我是什么样的人
-