最近各家公司都开始暑期实习的招聘了,在这里总结一下,题目来自本人或同学的面试,本人是大数据 + 后台方向
-
腾讯(后台开发一面)
-
了解哈希嘛?说说哈希在密码学中的应用?
将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值
应用:文件校验,数字签名
-
哈希什么情况下会发生碰撞,怎么样选取哈希的方式能让碰撞几率降低
其实根据鸽巢原理,哈希是一定会碰撞
如何减少碰撞概率,我觉得应该可以从三个方面考虑的:
- 增大 映射空间/原空间 的大小这个很明显,映射空间/原空间 的比值大,碰撞的概率就可能小了。 前面我们也提到过,当这个比值大于等于1时,就可以实现无碰撞。
- 尽可能把原数据集均匀映射到较小空间简单举个例子说明。比如有10个数,映射到5个位置。如果每个位置均匀对应2个数,那么任意选2个数,碰撞概率为0.2.如果1个位置对应6个数,其余4个位置各对应1个数,那么任意选两个数,碰撞概率为0.36
- 结合原空间数据的数据特征我们在处理原空间的数据集时,数据集一般都会有特征,而且不会是原空间的全集。换句话说,我们要处理的数据一般只会是原空间所有数据的一部分,而且数据集有一定特征(数据元素出现的概率的不同)。
一般哈希函数用质数取模这就是为了使得有特征的数据集也能均匀映射到映射空间。在这种情况下,有时hash函数还要结合数据特征,让出现概率较大的数据集有较小的碰撞概率,出现概率较小的数据集有较大的碰撞概率。这样,就可以减少整体数据集的碰撞概率。
-
说说平时用的排序算法的时间复杂度和空间复杂度
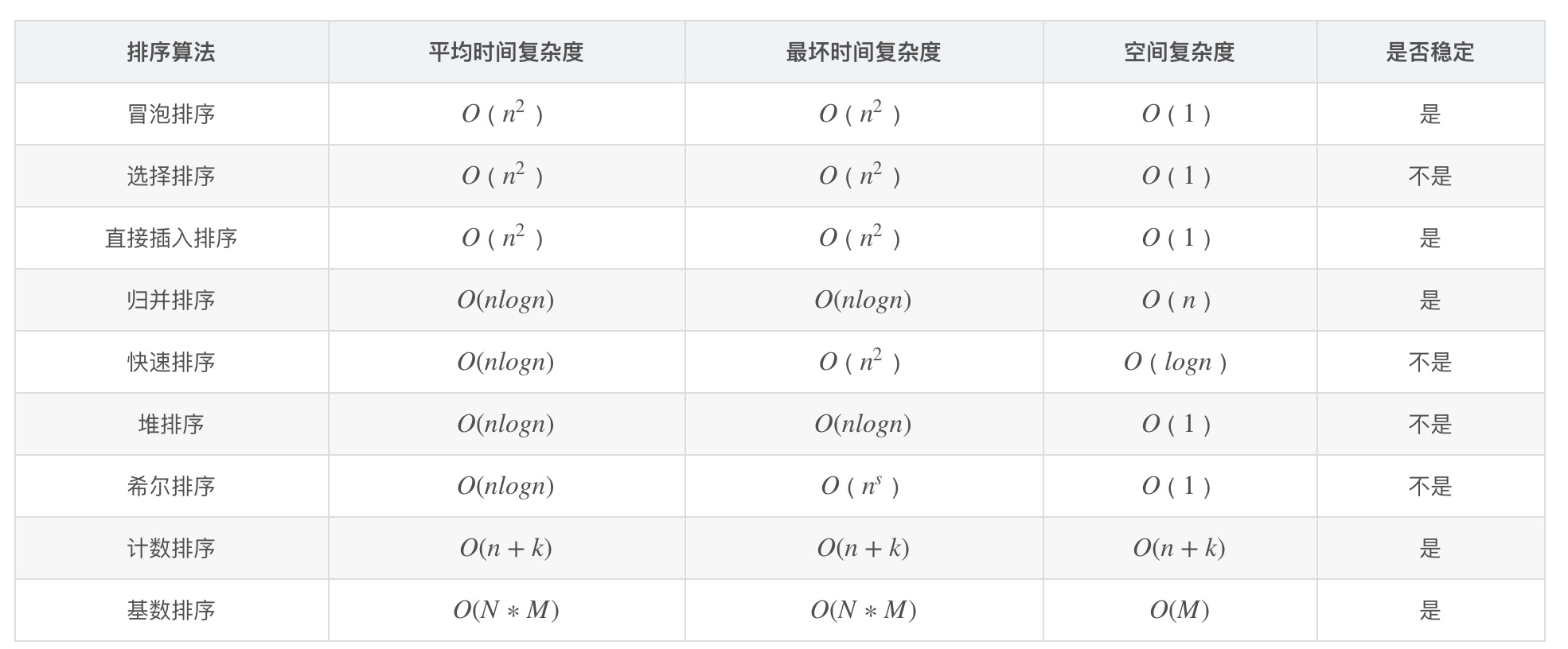
排序 是原地排序 是否稳定 最好 最坏 平均 冒泡 是 是 O(n) O(n^2) O(n^2) 插入 是 是 O(n) 从尾巴开始比较 O(n^2) O(n^2) 选择 是 否 O(n^2) O(n^2) O(n^2) 归并 不是 是 O(nlogn) O(nlogn) O(nlogn) 快速 不是 不是 O(nlogn) O(n^2) O(nlogn) 堆 是 不是 O(nlogn) O(nlogn) O(nlogn) 计数 不是 是 O(n + k) O(n + k) O(n + k) 基数 不是 是 O(m * n) O(m * n) O(m * n) -
写一个快排给我看
def quick_sort(arr, l, r): if l < r: pivot = partition(arr, l, r) quick_sort(arr, l, pivot - 1) quick_sort(arr, pivot + 1, r) def partition(arr, l, r): base = arr[r] j = l for i in xrange(l, r): if arr[i] < base: arr[i], arr[j] = arr[j], arr[i] j += 1 arr[j], arr[r] = arr[r], arr[j] return j -
进程间通信方式都有哪些?各自的优缺点是什么?
- 管道
- FIFO(命名管道)
- 消息队列
- 信号量
- 共享内存
- 套接字
-
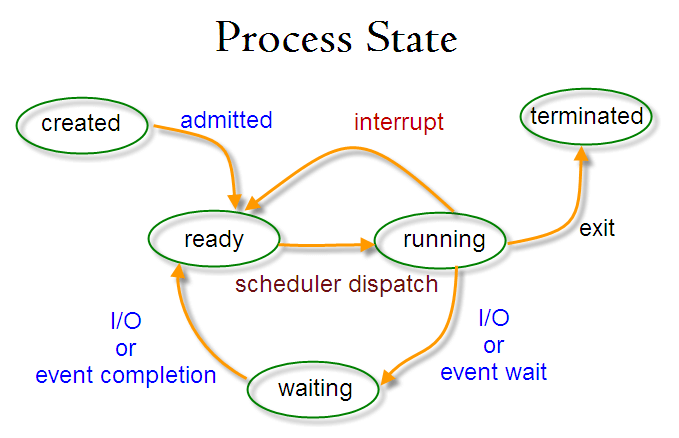
进程有几种状态,怎么转换的。
created,ready,running,terminated,waiting
-
进程什么情况下会死锁,怎么避免。
资源请求图中出现了环
赋予资源的时候,银行家算法去检测
-
说说TCP,UDP各自的特点,并举一个现实中的例子
- TCP 是面向连接的,可靠的连接,具有超时重传机制,具有流量控制和拥塞控制,单位是字节流,只能是一对一的(FTP,HTTP)
- UDP 是无连接的,尽最大可能交付,单位是数据报文,支持一对一,一对多,多对一,多对多(DHCP)
-
说一下TCP三次握手和四次挥手,并描述一下三次握手四次挥手时服务器和客户端各自的状态
-
TCP怎么保证可靠传输的
TCP 自带超时重传的机制,当报文段在超时时间内没有被确认,TCP 会重传这个报文,超时时间略大于报文段发送确认的往返时间
-
讲一讲TCP拥塞控制
慢开始,拥塞避免,快重传,快恢复
-
两个链表,如何判断他们是否有交点
- 如果可以改 ListNode 的实例(例如 Python),直接遍历其中一个链表,打上 tag,再遍历另外一个即可
- 如果不能,也可以用 hash 表的方式存储,比较耗内存
- 最后,可以用长短链表的思想,先计算两个链表的长度,然后让长链表先走长度差的步速,然后两个链表每次一步走,相遇了就是有交点
-
讲一下点击url打开网页的过程都发生了什么
-
讲一下DNS服务器的实现
-
你平时用的数据库是什么,讲讲MyISam和innoDB的区别
-
MyIsam
- 高性能读取
- 因为它保存了表的行数,当使用COUNT统计时不会扫描全表
- 锁级别为表锁,表锁优点是开销小,加锁快;缺点是锁粒度大,发生锁冲动概率较高,容纳并发能力低,这个引擎适合查询为主的业务
- 此引擎不支持事务,也不支持外键
- INSERT和UPDATE操作需要锁定整个表
- 它存储表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫
-
InnoDB
- 支持事务处理、ACID事务特性
- 实现了SQL标准的四种隔离级别
- 支持行级锁和外键约束
- 可以利用事务日志进行数据恢复
- 锁级别为行锁,行锁优点是适用于高并发的频繁表修改,高并发是性能优于 MyISAM。缺点是系统消耗较大
- 索引不仅缓存自身,也缓存数据,相比 MyISAM 需要更大的内存
-
-
主键,唯一索引,联合索引区别。
primary key unique key union key
-
如果一个表要做很多count操作,你应该用哪个引擎。
MyIsam,不用扫表就能获取 count 值
-
如果一个表要频繁做很多insert操作,并且经常查询count,你应该用哪个引擎
只要 insert 很频繁,使用 MyIsam 都不好,因为 MyIsam 的锁粒度是表锁。。
-
如果一个表要频繁做很多insert,update操作,并且经常会查询count,怎么实现好
将 count 数量放在上层中,更新下层表的时候,利用 MySQL 事务同时去更新上层表
-
你平时linux用的多吗,常用命令有哪些?查看硬盘状态命令是什么?查看一个进程端口号占用的命令是啥。
常用命令就不写了,毕竟 vim 一大堆
磁盘状态 top/free
进程端口号占用
lsof -i:进程号/ps aux | grep进程号 -
写一下判断数学表达式是否正确的程序
from collections import deque def solution(str): str = str.replace(' ', '') str_arr = str.split('=') if len(str_arr) != 2: return False l, r = str_arr[0], str_arr[1] op_stack = deque() num_stack = deque() ops = '+-*/' i = 0 l_len = len(l) while i < l_len: ch = l[i] if ch in ops: op_stack.append(ch) i += 1 elif '0' <= ch <= '9': j = i + 1 while j < l_len and '0' <= l[j] <= '9': j += 1 num = int(l[i:j]) if len(op_stack) > 0 and (op_stack[-1] == '*' or op_stack[-1] == '/'): tmp = num_stack.pop() res = tmp * num if op_stack[-1] == '*' else tmp / num op_stack.pop() num_stack.append(res) else: num_stack.append(num) i = j else: return False res = 0 while len(op_stack) != 0: if len(num_stack) < 2: return False m = num_stack.popleft() n = num_stack.popleft() op = op_stack.popleft() res = (m + n) if op == '+' else (m - n) num_stack.appendleft(res) return int(r) == res if __name__ == '__main__': print solution('1 + 2 * 3 = 7') print solution('1 + 4 / 2 + 3 + 2 * 4 = 14') print solution('1 + 8 - 4 / 2 + 8 * 9 - 3 = 76')
-
-
腾讯(C++ 一面)
个人觉得这套题不像是 C++ 的,像 Java –
-
HashMap的数据存储方式,最差访问复杂度,如何提高
拉链法 + 红黑树(JDK8 当单个 hash 槽有 16 个元素的时候,改为红黑树)
最差 O(n)
提高的话,提高散列因子,这样不会有很多的 hash 落到一个槽
自己实现的话,拉链 -> 跳表
-
TCP和UDP的区别,TCP如何确保可靠传输
TCP 通过出错重传保证可靠传输
-
GET POST 的区别
- 允许的实体大小不同
- 安全性不同
- Restful 中承担的责任不同 4. HTTPS如何保证加密传输
非对称加密 + 对称加密
-
实现一个函数,输入url,统计输入的url的次数,要求线程安全
上锁
go 的做法 type urlCount struct { hashMap map[string]uint64 sync.RWMutex } -
访问链表的倒数m个节点
快慢指针,一个先走 m 步,然后一起走,等先走 m 步的到终点了,后走的就找到了倒数第 m 个节点
-
快速求3的57次方
3 ^ n = 3 ^ (n / 2) * 3 ^ (n / 2) 当 n 为偶数
3 ^ n = 3 ^ (n / 2) * 3 ^ (n / 2) * 3 当 n 为奇数
-
一个2G的文件,里面全是数字,最大数字不超过long,没有重复数字,给这些数字排序,用什么方法
这道题应该有内存限制,没有的话,直接 2g 内存快排即可
有内存限制的话,桶排序
-
-
微信(后台开发一面)
-
实现一个函数,接受数组作为参数,数组元素为整数或者数组(数组里面还可能有数组),函数返回扁平化后的数组。要求给出不使用递归、不使用字符串处理的解法
[1, [2, [ [3, 4], 5, []], 6]],输出 [1, 2, 3, 4, 5, 6] from collections import deque def solution(arr): res = [] stack = deque([(arr, 0)]) while len(stack) > 0: cur_arr, idx = stack.popleft() for i in xrange(idx, len(cur_arr)): if type(cur_arr[i]) is not list: res.append(cur_arr[i]) else: stack.appendleft((cur_arr, i + 1)) stack.appendleft((cur_arr[i], 0)) break return res if __name__ == '__main__': arr = [1, [2, [ [3, 4], 5, []], 6]] print solution(arr) -
假设有一个升序数组,经过不确定长度的偏移,得到一个新的数组,我们称为循环升序数组,(例:[0,3,4,6,7] 可能变成 [6,7,0,3,4])
def binary_sort(arr, target): length = len(arr) l, r, m = 0, length - 1, -1 while l <= r: m = l + (r - l) / 2 if nums[m] == target: return True while l < m and nums[l] == nums[m]: l += 1 if nums[l] <= nums[m]: if target < nums[m] and target >= nums[l]: r = m - 1 else: l = m + 1 else: if target > nums[m] and target <= nums[r]: l = m + 1 else: r = m - 1 return False if __name__ == '__main__': arr = [6,7,0,3,4] target = 2 print binary_sort(arr, target) -
设计一个函数,用于测试请求一个 URL 的平均耗时。要求可以设置总的请求次数以及允许同时发出的请求个数。假设环境是小程序,使用的接口是 wx.request ,不考虑请求失败的情况
// wx.request 调用示例: // wx.request({ // url: 'https://qq.com', // success() { // // 请求完成 // } // }) /** * @synopsis 测试网络请求平均耗时 * * @param URL 请求的地址 * @param count 请求的总次数,取值范围 >= 1 * @param concurrentCount 允许最多同时发出的请求个数。取值范围 >=1 * * @returns 一个 Promise 对象,resolve 平均耗时 */ let curCount = 0; let sumTs = 0; const getPromise = (URL) => { return new Promise((resolve, reject) => { const beginTs = Date.now(); wx.request({ url: URL, success() { resolve(Date.now() - beginTs); } }); }); }; const fun = (URL, resolve) => { getPromise(URL).then(ts => { sumTs += ts; curCount += 1; if (curCount < count) { fun(URL); } else { resolve(sumTs / count); } }); } const solution = (URL, count, concurrentCount) => { return new Promise((resolve, reject) => { if (count <= concurrentCount) { for (let i = 0; i < count; i++) { getPromise(URL).then(ts => { sumTs += ts; }); } } else { for (let i = 0; i < concurrentCount; i++) { fun(URL, resolve); } } }); };
-
-
飞猪二面(Java)
-
shell 如何跳出循环
break 和 continue
-
shell 单双引号的区别
单引号是强引用,双引号是弱引用,单引号会转义,输入什么就输出什么,双引号内可以用
${}执行一些语句 -
exit(0) 和 exit(1) 的区别
exit(0) 代表正常运行程序并退出程序,exit(1) 代表非正常运行导致退出程序,exit(0)与exit(1)对你的程序来说,没有区别,对使用你的程序的人或者程序来说,区别可就大了。一般来说,exit 0 可以告知你的程序的使用者:你的程序是正常结束的。如果 exit 非 0 值,那么你的程序的使用者通常会认为你的程序产生了一个错误。以 shell 为例,在 shell 中调用完你的程序之后,用
echo $?命令就可以看到你的程序的 exit 值。在 shell 脚本中,通常会根据上一个命令的$?值来进行一些流程控制 -
数据库索引是怎么实现的?为啥不用B树和二叉树?
MySQL 的索引是 B+ 树实现的,不用二叉树的原因是数据量大的时候,二叉树层次太高,查询起来效率太低,不用 B树 的原因是,B树叶子节点没有相互指向的指针,范围查询效率不高,B树的非叶子节点同样存储数据,导致相比于B+树来说需要更高的层级来存储索引
-
Java CountDownLatch 类似于 Go 的 WaitGroup,用于主线程等待多个线程执行完毕的场景
CountDownLatch cdl = new CountDownLatch(2); Thread1 t1 = new Thread1(cdl); Thread1 t2 = new Thread1(cdl); t1.start(); t2.start(); cdl.await(); ... public Thread1 extends Thread { private CountDownLatch cdl; Thread1(CountDownLatch cdl) { this.cdl = cdl; } public void run() { ... this.cdl.countDown(); } }
-
微信三面(后台开发)
-
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个整数,并返回他们的数组下标。
def two_sum(nums, target): hash_map = {} for idx, n in enumerate(nums): if (target - n) in hash_map: return [hash_map[target - n], idx] else: hash_map[n] = idx return [-1, -1] if __name__ == '__main__': arr = [2, 7, 11, 15] target = 9 print two_sum(arr, target) -
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的
class ListNode(object): def __init__(self, v): self.v = v self.next = None def merge_list(l1, l2): if not l1: return l2 if not l2: return l1 res = ListNode(-1) tmp = res while l1 and l2: if l1.val <= l2.val: tmp.next = l1 l1 = l1.next tmp.next.next = None else: tmp.next = l2 l2 = l2.next tmp.next.next = None tmp = tmp.next if l1: tmp.next = l1 if l2: tmp.next = l2 return res.next -
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。最高位数字存放在数组的首位,数组中每个元素只存储一个数字
def num_arr_add_one(nums): length = len(nums) if length == 0: return nums if nums[0] == 0: return [1] idx = length - 1 while idx >= 0: nums[idx] += 1 if nums[idx] < 10: return nums nums[idx] -= 10 idx -= 1 nums.insert(0, 1) return nums if __name__ == '__main__': nums = [1, 2, 3] print num_arr_add_one(nums) -
给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素
class TreeNode(object): def __init__(self, v): self.v = v self.left = None self.right = None def kth_smallest_in_bst(root, k): if not root: return -1 res = [None, 1] def recursive(node): if not node or res[0] is not None: return recursive(node.left) if res[1] == k: res[0] = node.v return else: res[1] += 1 recursive(node.right) recursive(root) return res[0]
-
-
阿里一面(大数据)
-
MySQL 主键索引与唯一索引的区别
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的
- 唯一性索引允许空值,而主键列不允许
- 主键可以被其他表引用为外键,而唯一索引不能
- 一个表最多只能创建一个主键,但可以有多个唯一索引
-
MySQL Blob Text
- Blob 和 Text 区别
- blob和text类型是无法设置默认值的
-
MySQL TEXT数据类型的最大长度
- TINYTEXT/TINYBLOB 256 bytes 2**8
- TEXT/BLOB 65,535 bytes 2**16
- MEDIUMTEXT/MEDIUMBLOB 16,777,215 bytes 2**24
- LONGTEXT/LONGBLOB 4,294,967,295 bytes 2**64
-
无尽数据流 topk
小根堆,复杂度 nlogk
-
10亿个数字去重
- hash 成小文件
- bitset
- 布隆过滤器
-
Kafka 脑裂
脑裂在分布式系统中是很常见的一种现象,指的是当联系着的两个节点断开联系的时候,本来作为一个整体的系统,分裂为两个独立的节点,这时两个节点开始争抢公共资源,结果会导致系统混乱,数据损坏
- 可以通过第三方仲裁来从两个节点中选出一个可用的
- 采用 fencing 机制,最后采用活下来的那个
Kafka利用Zookeeper所做的第一件也是至关重要的一件事情是选举Controller,那么自然就有疑问,有没有可能产生两个Controller呢?
首先,Zookeeper也是有leader的,它有没有可能产生两个leader呢?答案是不会。quorum机制可以保证,不可能同时存在两个leader获得大多数支持。假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch,这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。那有没有follower不知道新的leader存在呢,有可能,但肯定不是大多数,否则新leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧leader即使各种认为自己是leader,依然没有什么作用。
Kafka的Controller也采用了epoch,具体机制如下:
- 所有Broker监控”/controller”,节点被删除则开启新一轮选举,节点变化则获取新的epoch
- Controller会注册SessionExpiredListener,一旦因为网络问题导致Session失效,则自动丧失Controller身份,重新参与选举
- 收到Controller的请求,如果其epoch小于现在已知的controller_epoch,则直接拒绝
理论上来说,如果Controller的SessionExpired处理成功,则可以避免双leader,但假设SessionExpire处理意外失效的情况:旧Controller假死,新的Controller创建。旧Controller复活,SessionExpired处理意外失效,仍然认为自己是leader。 这时虽然有两个leader,但没有关系,leader只会发信息给存活的broker(仍然与Zookeeper在Session内的),而这些存活的broker则肯定能感知到新leader的存在,旧leader的请求会被拒绝
-
-
阿里二、三面(大数据)
-
进程和线程的关系
-
mr 的过程
-
hive join 数据倾斜
-
Spark 宽窄依赖
-
算法题,aaabbcc -> a3b2c2,比较简单,不写了
-
算法题,求集合的全部子集
def solution(arr): res = [[]] length = len(arr) def recursive(idx, path): res[0].append(path) if idx == length: return for i in xrange(idx, length): recursive(i + 1, path + [arr[i]]) recursive(0, []) return res[0]
-
-
阿里四,五面(大数据)
-
如何设计一个 Web 后端 Server
MVC 框架 + MySQL + Redis + Metrics
-
MySQL 索引块为啥默认是 16k
是内存页大小的整数倍
-
MySQL 二次写
-
Spark Shuffle 过程
-
Spark 宽窄依赖有什么好处啊
并行计算 + 快速容灾
-
如何设计阿里妈妈的标签系统
可视化界面勾选维度,天级别定时跑任务
-
依旧是上面这个问题,那么有几万个定时任务,如何优化
可以从不同的 sql 中选出公共的 sql,跑出中间表,避免重复作业
-
-
网易游戏一面(大数据)
-
栈和队列的区别
先进后出和先进先出
-
LRU 如何实现
hash 表 + 链表
-
MySQL MVCC
-
MySQL 二次写
-
算法题,求陆地的范围
0 1 0 0 1 0 1 1 0 1 0 0求连续1的块数
dfs 很简单,不写了
-
归并排序
-
压缩一个树,树的数据结构如下所示,如果树节点的 value 为0且树没有孩子节点,则删除,需要从叶子节点递归上去
class TreeNode(object): def __init__(self, v): self.v = v self.children = [] def solution(root): if not root: return def recursive(node): length = len(node.children) if length == 0: if node.v == 0: return False return True tmp = [] for i in xrange(length): if recursive(node.children[i]): tmp += node.children[i], node.children = tmp return True if tmp or node.v != 0 else False recursive(root)
-
-
网易游戏二面(大数据)
-
实现一个生产者消费者,可以使用 BlockingQueue
public class ProducerConsumer { private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5); private static class Producer extends Thread { @Override public void run() { try { queue.put("product"); } catch (InterruptedException e) { e.printStackTrace(); } System.out.print("produce.."); } } private static class Consumer extends Thread { @Override public void run() { try { String product = queue.take(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.print("consume.."); } } } -
手动实现一个生产者消费者,不能用 BlockingQueue
import java.util.concurrent.ReentrantLock; import java.util.concurrent.Condition; class MQ { private ArrayList<Object> list; private ReentranLock lock; private Condition condition; private int cap; public MQ(int cap) { this.list = new ArrayList<Object>(cap); this.lock = new ReentrantLock(); this.condition = this.lock.newCondition(); this.cap = cap; } public void consumer() { this.lock.lock(); try { while (this.list.size() == 0) { this.condition.await(); } Object o = this.list.remove(0); this.lock.signalAll(); } catch (Exception e) { e.printStackTrace(); } finally { this.lock.unlock(); } } public void producer(Object o) { this.lock.lock(); try { while (this.list.size() == this.cap) { this.condition.await(); } this.list.add(o); this.lock.signalAll(); } catch (Exception e) { e.printStackTrace(); } finally { this.lock.unlock(); } } } public class Main { public static void main(String[] args) { } } -
两个线程分别打印26个英文字母的元音(a, e, i, o, u)和辅音(其他),按字母序输出
package main.multithread; import java.util.LinkedHashSet; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.ReentrantLock; public class AlphabetPrint { private final ReentrantLock lock = new ReentrantLock(); private final Condition printVowel = lock.newCondition(); private final Condition meetVowel = lock.newCondition(); public void execute() throws InterruptedException { final LinkedHashSet<Character> vowels = new LinkedHashSet<>(); for (char ch : new char[]{'a', 'e', 'i', 'o', 'u'}) { vowels.add(ch); } Thread vp = new Thread(new VowelPrint(vowels)); Thread cp = new Thread(new ConsonantPrint(vowels)); vp.start(); cp.start(); vp.join(); cp.join(); } class VowelPrint implements Runnable { private final LinkedHashSet<Character> vowels; VowelPrint(LinkedHashSet<Character> vowels) { this.vowels = vowels; } @Override public void run() { lock.lock(); try { for (char ch : vowels) { try { meetVowel.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.print(ch); printVowel.signal(); } } finally { lock.unlock(); } } } class ConsonantPrint implements Runnable { private final LinkedHashSet<Character> vowels; ConsonantPrint(LinkedHashSet<Character> vowels) { this.vowels = vowels; } @Override public void run() { lock.lock(); Boolean visitVowel = false; try { for (int i = 0; i < 26; i++) { char ch = (char)(i + 'a'); if (vowels.contains(ch)) { meetVowel.signal(); visitVowel = true; } else { if (visitVowel) { try { printVowel.await(); } catch (InterruptedException e) { e.printStackTrace(); } } visitVowel = false; System.out.print(ch); } } } finally { lock.unlock(); } } } }class Thread1 implements Runnable { private Semaphore semaphore1; private Semaphore semaphore2; private final char[] vowels = new char[]{'a', 'e', 'i', 'o', 'u'}; private final HashSet<Character> s = new HashSet<>(); public Thread1(Semaphore semaphore1, Semaphore semaphore2) { this.semaphore1 = semaphore1; this.semaphore2 = semaphore2; for (char ch : vowels) { s.add(ch); } } @Override public void run() { try { semaphore1.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } int i = 0; while (i < 26) { char ch = (char)(i + 'a'); if (s.contains(ch)) { semaphore2.release(); i += 1; } else { try { semaphore1.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } while (i < 26) { char c = (char)(i + 'a'); if (s.contains(c)) { break; } System.out.print(c); i += 1; } } } } } class Thread2 implements Runnable { private Semaphore semaphore1; private Semaphore semaphore2; private final char[] vowels = new char[]{'a', 'e', 'i', 'o', 'u'}; public Thread2(Semaphore semaphore1, Semaphore semaphore2) { this.semaphore1 = semaphore1; this.semaphore2 = semaphore2; } @Override public void run() { for (char ch : vowels) { try { semaphore1.acquire(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.print(ch); semaphore2.release(); } } } class Main { public static void main(String[] args) throws InterruptedException, ExecutionException { Semaphore vowel = new Semaphore(0); Semaphore common = new Semaphore(1); Thread t1 = new Thread(new Thread1(common, vowel)); Thread t2 = new Thread(new Thread2(vowel, common)); t1.start(); t2.start(); t1.join(); t2.join(); } } -
Java 基础
String a = "a"; String b = "a"; System.out.println(a == b); // true,a 和 b 引用都是指向 String pool Integer a = 1; Integer b = 1; System.out.Println(a == b); // true,a 和 b 自动装箱的时候会执行 Ineger.valueOf,这个会去 Integer 缓存池中取数,new Integer() 是创建新的 -
Java finally 和 finalize 有什么区别
finally 是配合 try catch 使用的,无论是否捕获异常,Java 都会执行 finally 块中的代码,经常将锁的释放,连接池的释放放在 finally 中执行
finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法,当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”
-
MySQL char 和 varchar 的区别,varchar 是变长的,char 是定长的
-
MySQL 非空CHAR的最大总长度是255字节,非空VARCHAR的最大总长度是65533字节 可空CHAR的最大总长度是254字节,可空VARCHAR的最大总长度是65532字节,原因:非空标记需要占据一个字节,VARCHAR超过255需要用2个字节标记字段长度,不超过255用1个字节标记字段长度,varchar(128) 表示能存 128 个 字符
-
Redis zset 数据结构
跳表
-
Redis 分布式锁如何实现
主要需要 setnx 和 expire time 的思想,需要将这两个操作放在一个 set 指令中执行,保证原子性
-
算法题
有 m 个字符,没有重复,求有多少种做法组成一个长度为 n 的字符串,要求用上全部 m 个字符,n >= m
这道题用暴力 DFS + 去重 可以做,但是复杂度太高了
其实这是一道数学题,我们可以考虑逆向思维,用全集减去仅仅使用 m - 1 个字符 + 使用 m - 2 个字符 - 使用 m - 3 字符
ans = m**n - C(m, 1) * (m - 1) ** n + C(m, 2) * (m - 2) ** n ...
-
-
快手一、二面(大数据)
-
hadoop 的推测执行
推测执行(Speculative Execution)是指在集群环境下运行 MapReduce,可能是程序 Bug,负载不均或者其他的一些问题,导致在一个 JOB 下的多个 TASK 速度不一致,比如有的任务已经完成,但是有些任务可能只跑了10%,根据木桶原理,这些任务将成为整个 JOB的短板,如果集群启动了推测执行,这时为了最大限度的提高短板,Hadoop 会为该 task 启动备份任务,让 speculative task 与原始 task 同时处理一份数据,哪个先运行完,则将谁的结果作为最终结果,并且在运行完成后 Kill 掉另外一个任务。
推测执行(Speculative Execution)是通过利用更多的资源来换取时间的一种优化策略,但是在资源很紧张的情况下,推测执行也不一定能带来时间上的优化,假设在测试环境中,DataNode 总的内存空间是40G,每个 Task 可申请的内存设置为1G,现在有一个任务的输入数据为5G,HDFS 分片为128M,这样 Map Task 的个数就40个,基本占满了所有的DataNode节点,如果还因为每些 Map Task 运行过慢,启动了 Speculative Task,这样就可能会影响到 Reduce Task 的执行了,影响了 Reduce 的执行,自然而然就使整个 JOB的执行时间延长。所以是否启用推测执行,如果能根据资源情况来决定,如果在资源本身就不够的情况下,还要跑推测执行的任务,这样会导致后续启动的任务无法获取到资源,以导致无法执行。
-
HDFS 的高可用性保证
-
NameNode
NameNode 的话,会有一个 secondNameNode 的存在,secondNameNode 中有一个 fsimage 存放元信息,有一个 editlogs 存放对元信息的操作,secondNameNode 会定期去 NameNode 上同步 editlogs,并更新 fsimage,一旦有了新的 fsimage 文件,将其写回 NameNode,NameNode 挂了之后重新启动可以根据 fsimage 快速恢复现场
-
DataNode
DataNode 默认会对每个 block 存储备份 3 块,leader 挂掉之后, DataNode 和 NameNode 的心跳连接能够知道,能够将元信息中对应的 leader 路径进行更改
-
-
HDFS 的联盟模式
文件的元数据是放在namenode上的,只有一个Namespace(命名空间)。随着HDFS的数据越来越多,单个namenode的资源使用必然会达到上限,而且namenode的负载能力也会越来越高,限制HDFS的性能。
Federation即为“联邦”,该特性允许一个HDFS集群中存在多个NameNode同时对外提供服务,这些NameNode分管一部分目录(水平切分),彼此之间相互隔离,但共享底层的DataNode存储资源
-
进程、线程以及协程之间的关系
-
tcp 的11种状态
-
tcp 出现大量 TimeWait 状态是为什么,如何解决
有可能网络出现问题,有可能 Server 端代码有问题,没有释放,有可能被 ddos 攻击了,可以将等待的时间调低,也可以设置 tcp 的 reuse
-
HDFS 的写入
先去 NameNode 中查询,再去 DataNode 中写入,我遗漏了两点,一是 block 大小默认是 128M,需要分片上传,二是 DataNode 默认会有副本,需要讲出来这个过程
-
写 sql
有一个表,字段是 uid,p_date,kpi,kpi 是百分制的,60分合格,一周有4天合格算达标,一年只要有一周达标就达标,求出达标的人群
select distinct uid from t group by uid, week(p_date) having sum(if (kpi >= 60, 1, 0)) >= 4; -
写 sql,如果需要连续4天才算合格,求出达标的人群,写窗口函数
select distinct c.uid as uid from ( select uid, sum(if (kpi >= 60, 1, 0)) over(partition by uid, weekofyear(from_unixtime(p_date)) order by p_date rows between 3 preceding and current row) as s from t ) c where c.s >= 4; -
写 sql
有一个表,字段是 uid,login_time,logout_time,p_date 求最大同时在线人数
SELECT MAX(a.online_nums) as max_online_nums FROM ( SELECT SUM(index) over (ORDER BY ts) as online_nums FROM ( SELECT unix_timestamp(login_time) as ts, 1 as index FROM t WHERE p_date = "20190412" UNION ALL SELECT unix_timestamp(logout_time) as ts, -1 as index FROM t WHERE p_date = "20190412" ) a ) b -
算法题,判断回文数,比较简单,不写了
-